如何把一个人过成一支队伍?至少在声音领域,腾讯音乐天琴实验室自研的语音合成大模型——琴语大模型做到了。
目前,国内外大厂都在语音大模型这条路上越走越远,有的严抠字错率百分比,有的追求语音克隆更高的相似度,通过“单点突破”形式抢占语音大模型头部位次。
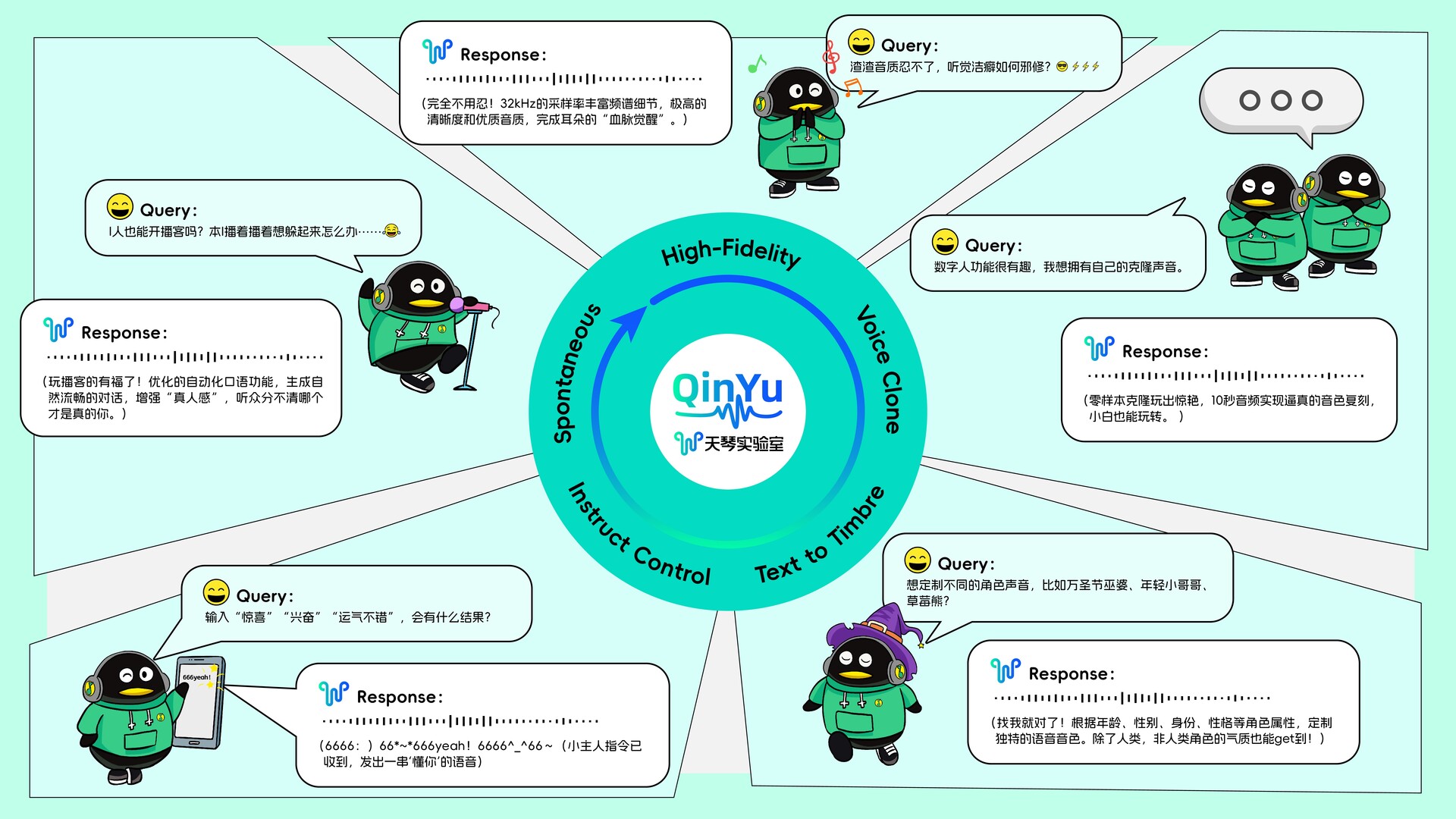
与之前的语音大模型不同,琴语大模型除了追求细节,更在功能的全面性、语音人格化的多样性上有全新突破。升级版的琴语大模型,融合32K高音质、零样本克隆、指令控制、音色生成、自动口语化等能力,让声音轻松复制、模仿、拟人,实现“分身”,琴语大模型也成为当今语音大模型第一梯队的“五边形战士”。
琴语大模型可不只是字面意义上的“琴”和“语”,实际上,它的能力非常广泛,而且声音品质和运行速度惊人。点击下方链接,一览琴语大模型主要功能。
琴语大模型demo页:
https://tme-lyra-lab.github.io/

琴语大模型TTS的C端能力很强大,通过以下链接,普通用户可以体验AI播客、音色克隆、有声书创作等功能,专业人员可以使用语音合成能力。
琴语TTS(C端用户可使用):
https://lyralabs.qq.com/index.html

琴语大模型背后的技术创新
琴语大模型具备多项领先的技术特性,核心亮点在于32k高音质、高自然度及零样本克隆能力。
高音质方面,32kHz的采样率使频谱细节更丰富,呈现出极高的清晰度和优质音质,能为用户带来卓越的听觉体验。
声音克隆方面,琴语大模型将克隆技术做到“零样本”,仅需约10秒的音频,就能实现极为逼真的音色复刻,大大降低语音克隆的门槛和成本。
指令控制方面,琴语大模型支持通过自然语言描述,实现精细化情感控制。自然语言描述分为情感描述和场景描述,输入“惊喜”“兴奋”等情感类词汇,以及“意外获得好消息”“看来我的运气不错”等场景类词汇,就能合成出符合要求的语音,极大提升语音合成的灵活性和适应性。
音色生成也是琴语大模型的重要能力,根据年龄、性别、身份、性格等角色属性,可为不同角色定制独特的语音音色。无论是孩童的娇憨、青年的温婉、中年的坚韧,还是老年的威严,亦或非人类角色的独特气质,都能通过模型生成相应的语音标识,为内容创作提供丰富的声音资源。
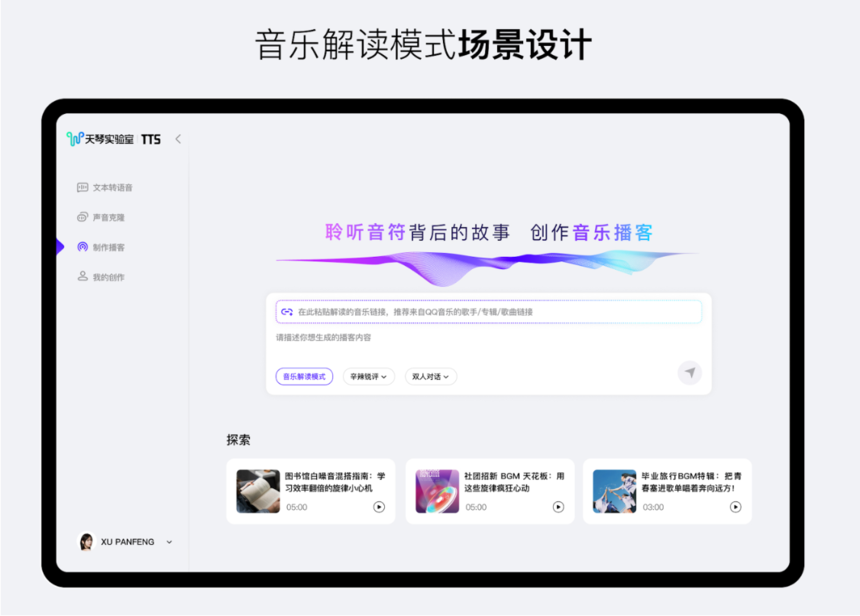
专为播客场景优化的自动口语化功能,能生成自然流畅的对话,带有自发的口语化现象。这一功能提高了拟人度,让听众在收听播客时感受到更真实、亲切的交流氛围。今年3月,QQ音乐在行业内首创推出“AI音乐播客”,通过琴语大模型与DeepSeek、文曲大模型的协同,实现“音乐+深度解读”的沉浸式收听体验。用户在QQ音乐搜索“听见音乐”,或在音乐榜单解读中,都可以使用“AI音乐播客”功能,并获得全新的自动口语化体验。

不仅如此,琴语大模型还为开发者提供了直观了解和体验其技术魅力的窗口,带来上百种音色的语音合成能力,满足人们在不同场景下对声音风格的多样化需求。开发者将拥有更灵活、强大的技术工具,探索更多创新应用方向。
想了解更多琴语大模型内容,请点击下方链接浏览:
https://lyralabs.qq.com/index.html
关键词:






















 营业执照公示信息
营业执照公示信息