“在百度语言与知识技术的布局和发展中,我们始终在注意把握两个趋势,即技术发展趋势和产业发展趋势,并力争引领趋势。”8月25日,在百度大脑语言与知识技术峰会上,百度CTO王海峰解读百度语言与知识技术的发展历程与最新成果。

在他看来,语言与知识技术是人工智能认知能力的核心,以语言和知识为研究对象,让机器像人一样掌握知识、理解语言的自然语言处理技术,对于人工智能发展至关重要。“历经近十年发展,百度已经构建了完整的语言与知识技术布局,包括知识图谱、语言理解与生成技术,以及上述技术所支持的包含智能搜索、机器翻译、对话系统、智能写作、深度问答等在内的的应用系统。”
据介绍,十年来,百度大脑语言与知识技术成果丰硕,获得包括国家科技进步奖在内的20多个奖项,30多项国际竞赛冠军,发表学术论文超过300篇,申请专利2000多项。技术不断突破创新的同时,也在产品上创新探索,同时将领先的技术输出给开发者与合作伙伴,提升各行业智能化水平。
王海峰表示:“知识图谱是机器认知世界的基础。机器认知能力的突破,越来越依赖对知识和大规模知识图谱的运用。百度打造了世界上最大的多源异构知识图谱,拥有超过50亿实体和5500亿事实,并在不断演进和更新,已应用于各行各业,每日调用次数超过400亿次。”
值得关注的是,针对不同应用场景和知识形态,百度建立起多样化的知识图谱类型,既有基础的实体知识图谱,也有行业知识图谱、事件图谱、关注点图谱等,以及融合语音、视频、图片的多模态知识图谱。而这背后是百度创建的包括无标签大数据开放知识挖掘技术、知识体系自扩展的知识图谱自学习技术、以及融合多源异构数据的知识补全与整合技术在内一整套知识图谱构建方法。
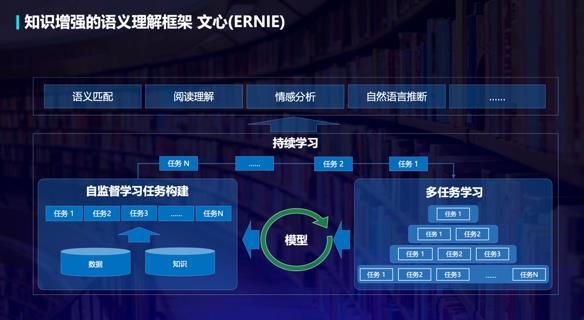
另外,百度研制了知识增强的跨模态深度语义理解方法,通过知识关联跨模态信息,运用语言描述不同模态信息的语义,进而让机器实现从“看清”到“看懂”、从“听清”到“听懂”,即图像和语言、语音和语言的一体化理解。而融合场景图知识的跨模态语义理解预训练技术,则大幅提升了跨模态推理能力。
王海峰指出,通过知识图谱、语言理解和跨模态语义理解等技术,智能搜索帮助用户更加高效、精准、便捷地获取知识和信息。百度提出了知识图谱驱动的对话控制技术,以及首个基于隐空间的大规模开放域对话模型PLATO等,并推出智能对话定制和服务平台UNIT,可帮助开发者高效构建智能对话系统,实现规模化应用。百度翻译支持200多种语言,每天响应超过千亿字符的翻译请求,支持超过40多万家第三方应用,技术上,提出了多智能体联合学习、基于语义单元的同传模型、稀缺语种分组混合训练算法等。
此外,百度语言与知识技术的成果,也在源源不断通过开源开放平台对外输出,在互联网、金融、医疗、教育等诸多领域发挥作用,提升产业智能化水平的同时,也得到了各方认可,这是近十年来百度语言与知识技术不断进步的最佳证明。
最后,王海峰对语言与知识技术的进一步发展做了展望。“复杂知识表示和快速构建技术,知识与深度学习 进一步融合,深度融合感知和认知的跨模态语义理解技术,模型可解释性和鲁棒性等,仍有很多技术难题需要持续研究和解决。但对于未来,百度充满信心,愿始终坚持探索机器‘掌握知识、理解语言、拥有智能’。”
关键词: 王海峰























 营业执照公示信息
营业执照公示信息